
Recent conditional diffusion models have shown remarkable advancements and have been widely applied in fascinating real-world applications. However, samples generated by these models often do not strictly comply with user-provided conditions. Due to this, there have been few attempts to evaluate this alignment via pre-trained scoring models to select well-generated samples. Nonetheless, current studies are confined to the text-to-image domain and require large training datasets. This suggests that crafting alignment scores for various conditions will demand considerable resources in the future. In this context, we introduce a universal condition alignment score that leverages the conditional probability measurable through the diffusion process. Our technique operates across all conditions and requires no additional models beyond the diffusion model used for generation, effectively enabling self-rejection. Our experiments validate that our metric effectively applies in diverse conditional generations, such as text-to-image, {instruction, image}-to-image, edge/scribble-to-image, and text-to-audio.
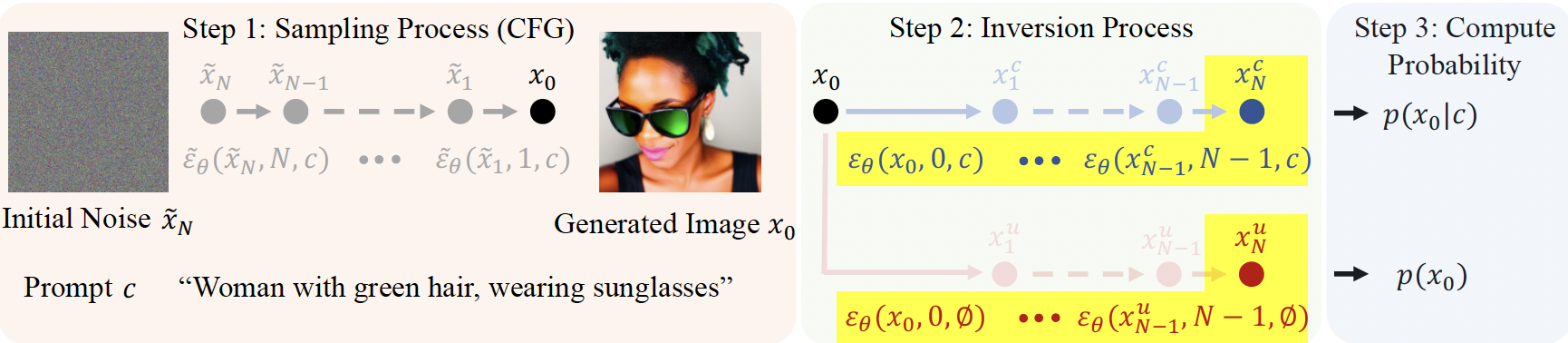
We hypothesized that the conditional likelihood is biased by the unconditional likelihood and validated this hypothesis through experimentation. Consequently, we adopted the difference between the conditional and unconditional likelihoods as a metric. The likelihood was calculated by applying the instantaneous change of variables formula to the DDIM ODE. The formula for CAS is given by: \[ CAS(\mathbf{x},\mathbf{c},\theta) = \log \frac{p_1(\mathbf{x}^{c}(1)|\mathbf{c})}{p_1(\mathbf{x}^{u}(1))} - \int_0^1 \alpha'(t)\frac{\nabla_\mathbf{x} \cdot \epsilon_{\theta}(\mathbf{x}^c(t), c, t) - \nabla_\mathbf{x} \cdot \epsilon_{\theta}(\mathbf{x}^{u}(t), \emptyset, t)}{2\alpha(t)\sqrt{1-\alpha(t)}}dt. \] The calculation of \(\nabla_\mathbf{x} \cdot \epsilon_{\theta}(\mathbf{x}^c(t), c, t)\) was performed using the Skilling-Hutchinson trace estimator \(\mathbb{E}_{p(\mathbf{z})}[\mathbf{z}^\top\nabla_\mathbf{x} \epsilon_\theta(\mathbf{x},t)\mathbf{z}]\). To improve inference time, instead of calculating the gradient of \(\epsilon_{\theta}\) through backward propagation, we approximated it using \(\mathbf{z}^\top \nabla_\mathbf{x} \epsilon_{\theta}(\mathbf{x}, t) \mathbf{z} \simeq \mathbf{z}^\top\frac{\epsilon_{\theta}(\mathbf{x}+\sigma \mathbf{z}, t)-\epsilon_{\theta}(\mathbf{x}, t)}{\sigma} = \frac{1}{\sigma} \mathbf{z}^\top(\epsilon_{\theta}(\mathbf{x}+\sigma \mathbf{z}, t) - \epsilon_{\theta}(\mathbf{x}, t))\). Additionally, we utilized the Simpsons 3/8 rule in the integration process.
Our experiments demonstrated the Conditional Alignment Score (CAS)'s effectiveness across five distinct models, with a particular focus on the T2I diffusion model fine-tuned in the Van Gogh domain. CAS outperformed established baselines such as CLIP Score, Human Preference Score, Image Reward, and Pick Score by a significant margin, especially notable in the Van Gogh dataset where it showed approximately 7.4% higher accuracy than the next best method. This success underscores CAS's unique ability to accurately measure style fidelity and text-to-image (T2I) alignment without requiring additional model training. Our method's robustness is further highlighted through experiments utilizing negative weighting on prompts, effectively demonstrating CAS's precision in evaluating domain-specific styles. Remarkably, CAS achieved this superior performance without relying on the extensive training datasets necessary for other metrics, indicating its efficiency and potential for broader application in generative modeling.

Extending our evaluation to additional modalities, including InstructPix2Pix, ControlNet, and AudioLDM, reaffirmed CAS's universal applicability. Human preference evaluations across these modalities revealed a consistent preference for outputs ranked highly by CAS, indicating its alignment with human judgment even in ambiguous conditions. Specifically, the experiments showed over 60% preference accuracy for CAS across different input-output pairs, signifying its effectiveness in capturing the nuanced preferences of human evaluators. The results from modalities beyond image generation, such as text-to-audio with AudioLDM, further validated the metric's versatility. Additionally, in the context of InstructPix2Pix, CAS's correlation with directional CLIP similarity provided empirical evidence of its reliability in measuring alignment, showcasing its capacity to serve as a comprehensive evaluation tool for a wide range of diffusion models.








@inproceedings{
hong2024CAS,
title={CAS: A Probability-based Approach for Universal Condition Alignment Score},
author={Chunsan Hong and Byunghee Cha and Tae-Hyun Oh},
booktitle={International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=E78OaH2s3f}
}